I am drafting my GSoC 2026 proposal for the Controller Area Network (CAN) Stack Improvements project (Issue #5440).
One of the key challenges identified in the new CAN stack adoption is the dependency on physical hardware (e.g., BeagleBone, specialized PCI cards) for testing. This currently prevents automated regression testing in the RTEMS CI/CD pipelines.
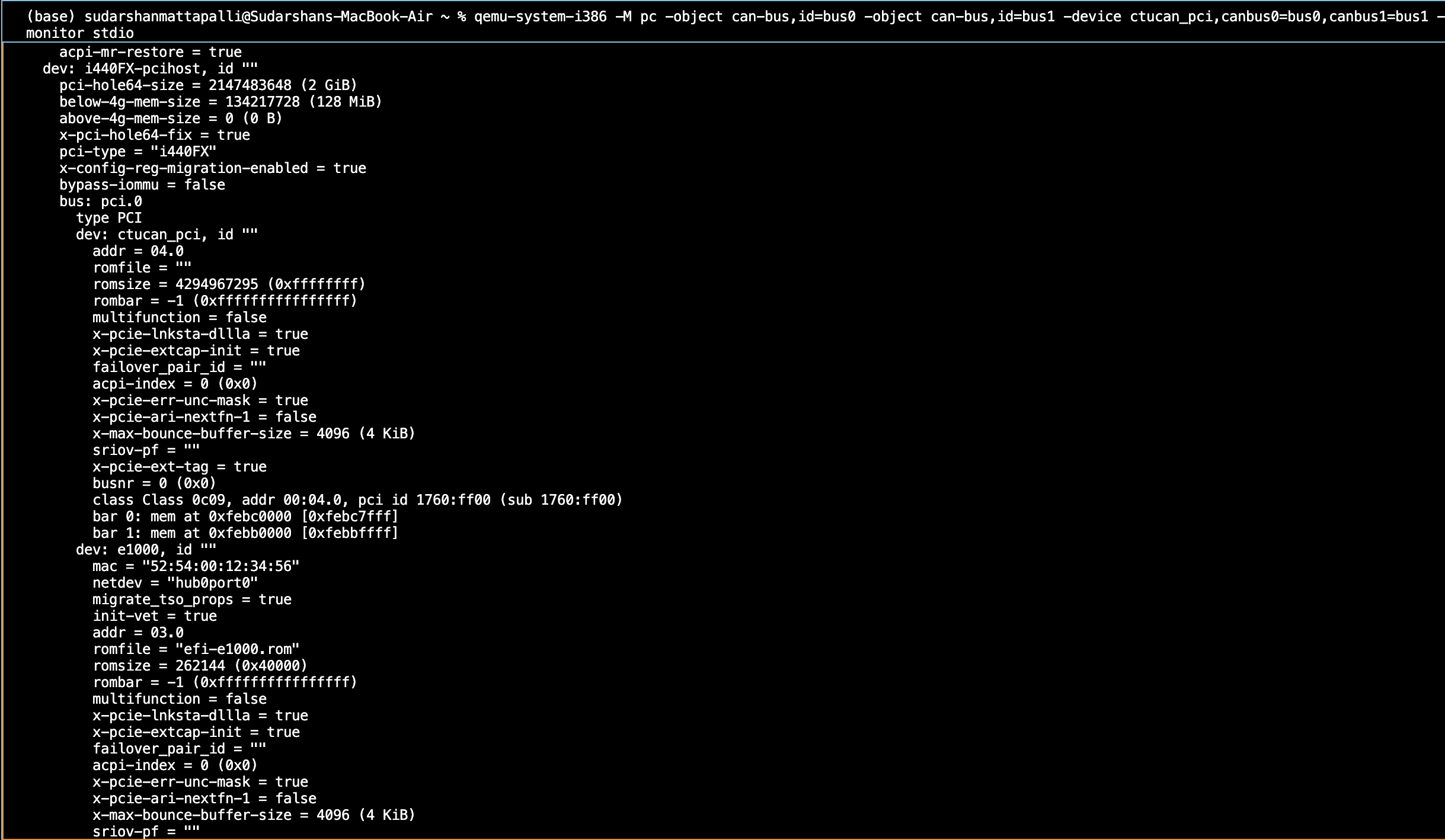
Progress on Virtualization & CI Strategy: To address this, I have successfully established a virtualization workflow using QEMU 10.2.1 and the CTU CAN FD PCI emulation. I have verified that the ctucan_pci device can be correctly instantiated, enumerated on the PCI bus, and attached to a virtual CAN bus on the pc386 BSP.
Proposal Focus: My proposal will center on two main pillars:
CI Infrastructure: Integrating this QEMU workflow into rtems-test to enable “hardware-free” regression testing for the CAN stack.
Concurrency Hardening: Addressing race conditions in the stack initialization and frame processing paths (building on my previous fix in MR !1059).
I would appreciate any feedback from the mentors (@pisa, @lenc, @gedare) on this virtualization approach. Does establishing this “Virtual Lab” align with the project’s immediate priorities?
Hello, nice work with establishing CT CAN FD virtualization! The automated tests are indeed needed, because now CAN stack is not tested at all (apart from few the tests I perform manually when I review the patches).
They are with complete build system, you can either try to use it (refer to readme file, there are description and scripts for i386 QEMU build, or you can copy the files to your preferable environment, it’s up to you. You are mostly interested in can_ctucanfd_pci.c file that initializes CTU CAN FD on RTEMS over PCI and then can_test.c file - this implements one way and two way communication tests. File can_register.c takes care of the initialization based on the argument.
The test applications can be run with following commands:
# this registers two CTU CAN FD controllers under dev/can0 and dev/can1
SHLL [/] # can_register -t ctucanfd_pci
# assign dev/can0 and dev/can1 to test applications
SHLL [/] # can_set_test_dev /dev/can0 /dev/can1
# run test applications
SHLL [/] # can_1w
SHLL [/] # can_2w
My general idea is to integrate those applications to RTEMS and change them in a way they provide coverage for most of the stack functionalities. These tests could then run in QEMU in rtems-tests as you pointed out.
Feel free to let me know if you have some questions or need help.
I have successfully built and executed the rtems_can_test application using QEMU (pc386) with the virtual CTU CAN FD PCI devices.
To get this running smoothly on macOS, I implemented a few workarounds:
Linker Resolution: The PCI registration was being stripped out during compilation, so I explicitly added #define BSP_WITH_PCI 1 in can_ctucanfd_pci.c.
Automated Testing: Due to a QEMU serial input bug on macOS dropping keystrokes, I bypassed the shell and automated the requested test sequence (can_ctucanfd_pci_register(), can_set_test_dev, and can_test_1w) directly inside init.c.
Here is the terminal output proving the driver initialization and frame transmission:
--- Automating CAN Tests ---
CTU CAN FD over PCI registered at dev/can0 and dev/can1
Setting CAN paths for tests to /dev/can0 and /dev/can1
can_test_1w: params: count 2000 delay 1, burst 100
--- CAN Tests Completed! ---
1: write done
can_monitor: sqn 0: /dev/can0 received = 0, sent = 100
can_monitor: sqn 1: /dev/can1 received = 0, sent = 0
can_monitor: sqn 0: /dev/can0 received = 0, sent = 400
can_monitor: sqn 0: /dev/can0 received = 0, sent = 700
can_monitor: sqn 0: /dev/can0 received = 0, sent = 1000
can_monitor: sqn 0: /dev/can0 received = 0, sent = 1300
can_monitor: sqn 0: /dev/can0 received = 0, sent = 1600
can_monitor: sqn 0: /dev/can0 received = 0, sent = 1900
0: write done
can_monitor: sqn 0: dev = /dev/can0 received = 0, sent = 2000, took 79650266 ns
0: fd closed from monitor
(Note: /dev/can0 successfully sent 2,000 frames. /dev/can1 received 0 because my QEMU launch command assigned them to isolated virtual buses (id=bus0 and id=bus1). I will map them to the same bus for loopback testing next.)
Now that my QEMU testbed is fully operational, my immediate goal is to submit meaningful patches to the CAN stack. I want to ensure my proposal aligns perfectly with the subsystem’s roadmap.
I am reviewing the RTEMS tracker for open CAN issues, could you share what you consider the most critical missing features or bottlenecks right now? Whether it is expanding POSIX compliance, refining the virtual CAN routing, or hardening error handling, I am ready to start prototyping a solution.
I am reviewing the RTEMS tracker for open CAN issues, could you share what you consider the most critical missing features or bottlenecks right now? Whether it is expanding POSIX compliance, refining the virtual CAN routing, or hardening error handling, I am ready to start prototyping a solution.
The missing part are the tests and some simple examples showing how to work with the CAN stack - I think that’s the place we should begin with. Provide proper testing as part of GSoC and then decide what needs to be changed/fixed based on those tests.
Also if you run into some troubles with CTU CAN FD communication/virtualization, you can try can_virtual.c - it’s a simple virtual controller that can be run on any RTEMS supported hardware or in QEMU for any RTEMS target - it doesn’t use some stack features that CTU CAN FD uses though, for example message abort, error filtering etc. These could be potentially simulated in the virtual controller however.
Using can_virtual.c as you suggested, I created a minimal hello_can application and opened a Merge Request in rtems-examples here: (MR!22). It demonstrates initializing the virtual controllers, registering the buses, and executing basic POSIX I/O in QEMU. (I also patched a missing <stdlib.h> in x86_display_cpu while I was in the repo).
Hope this hello_can example aligns with what you had in your mind!
I have incorporated your suggestions and restructured my project to focus entirely on integrating rtems_can_test for QEMU execution and upgrading can_virtual.c for fault simulation.
I have a few quick questions to ensure my approach aligns with the expectations:
1. Handling Hardware-Specific Tests Since the ported rtems_can_test applications will specifically need the CTU CAN FD PCI model, what is the standard way to ensure they don’t break the “run everywhere” rule on other boards? Should the test code dynamically check for the hardware and skip itself if it’s missing, or is it better to exclude these tests at the build level (e.g., using .tcfg files)?
2. QEMU and RSB Support Does the default QEMU built by the RTEMS Source Builder (RSB) already have the CTU CAN FD PCI model enabled? I just want to know if I should allocate time in my schedule to submit patches to RSB to get it working for the automated runners.
3. Location for Simple Examples As Michal suggested, I will be adding some simple examples to show developers how to use the CAN stack. Would testsuites/samples be the best place to put these so they stay separate from the heavy regression tests?
4. Priorities for Virtual Fault Simulation When I upgrade can_virtual.c to simulate hardware errors , are there any specific error states—such as forcing a Bus-Off state—that you’d like me to prioritize testing first?
Ask about question 1 in General. I think this is a broadly relevant question beyond the scope of just your work.
Ask about question 2 in Source Builder or even on Discord, for the same reason, but I think the answer is no.
Regarding question 3, those kinds of examples are better put in rtems-examples.git.
For the faults, I would certainly say exercising the fault confinement state machine to test the error active/passive and bus-off states is a good place to start. Beyond that I guess it is just a matter of working through different kinds of faults/errors. You might also test misconfiguration (e.g., mismatched bitrate).
Thanks for the clear direction, Gedare. I have updated my proposal to target rtems-examples.git and specifically included the fault confinement state machine and bitrate misconfigurations . I have opened separate threads in General and Source Builder for the structural questions!
Thank you for the guidance over the last few weeks.I have integrated all your feedback into my final draft
As the GSoC submission deadline approaching, I have finalized my proposal: [Draft proposal ]
Before I submit it to the Google portal , I just wanted to do a final sanity check:
Does the finalized timeline and workload align well with the expectations for a Large (350-hour) project? Are there any critical omissions or adjustments you would like to see?
I expect that the CTU CAN FD QEMU support is included for every target which offer PCI.
config CAN_CTUCANFD
bool
default y if PCI_DEVICES
select CAN_BUS
or at least this was our goal. The QEMU sources/version have to be at least v5.2.0. It has been released five years ago. So I expect that it has propagated to all non-ancient distributions and builds.
The limitation is that connection to the host system CAN bus is implemented only for Linux and SocketCAN API. But suggest to test subsystem by configuring two controllers to be connected to the single QEMU can-bus object and then communication between two or even more controllers can be tested from within running RTEMS application.
Thank you for confirming the native QEMU PCI support.
My proposal currently plans exactly what you suggested: configuring multiple virtual CTU CAN FD controllers on a single QEMU can-bus object to validate multi-node communication directly within the RTEMS environment, completely bypassing the Linux host limitations.
Some ideas about the utilities and tests which I consider useful:
provide some set of shell utilities which can be registered into RTEMS shell.
I would model their interface on base of the Linux CAN Utilities, see Manpages of can-utils in Debian testing — Debian Manpages
They are intended for SocketCAN API and style of work but most of their options could apply to the other CAN stacks easily. The first two to start with are candump (candump.c) and cangen (cangen.c). Main user visible change for RTEMS and other character driver CAN API would be change of interface specification from canX network interface to /dev/canX device. In the theory, some code (i.e. commandline parsing) can be reused directly from the sources, they has been provided under BSD like license (with GPL as alternative) by Oliver Hartkopp (Volkswagen Group Electronic Research) and Marc Kleine-Budde (Pengutronix). But I would start wit simpler version from the scratch. I would suggest the broad license if started from scratch because then the tools can be reused for different character driver based stack. /* SPDX-License-Identifier: BSD-2-Clause OR Apache-2.0 OR GPL-2.0-or-later */
There is even option to update and base the tools on our ancient OrtCANlibVCA infrastructure which would allow to use them with Linux char-dev and SocketCAN stacks as well as with both APIs on NuttX and RTEMS API. But FD support needs to be added in such case to OrtCAN. But for tools intended for RTEMS mainline, I lean a little more toward striving to keep them simple without an abstraction layer and rewrite them for a specific API.
the can_1w and can_2w tests could/should be included in RTEMS mainline almost directly.
Something like can_latency worth to be included as well
simple gateway, for start even without any configuration, which sends all frames from one interface to another is necessary to include RTEMS in the latency testing system, see CTU CAN bus project page section about CAN Bus Channels Mutual Latency Testing. We run that for Linux mainline and RT kernels daily and I am sure that RTEMS would shine in this area there on the same hardware which could be good impulse for Linux community, including us, to do something with that on the Linux side.
Thank you for the detailed suggestions and reference links.
To maintain a realistic 350-hour scope, I have updated my proposal to include developing permissively-licensed, from-scratch versions of candump and cangen as part of the Phase 1 deliverables, alongside the can_1w and can_2w integration.
I have added the more advanced tools (can_latency, canping, and the CAN gateway) to the “Future Improvements” section.
Thanks for the reminder!
The Google submission form explicitly asks for a “GitHub” username and URL. Since all my RTEMS contributions and tracking are on the RTEMS GitLab, is it preferred that I paste my RTEMS GitLab URL into those GitHub fields, or should I just give my GitHub URL?
Correct. @mithileshm if it’s optional you can omit it, otherwise you can put in your github url. We collect the information we want in the proposal document.
I successfully moved the can_1w and can_2w logic into the native sptests framework as spcan03 and spcan04. Both tests compile via Waf and are currently passing concurrent stress tests headless on the sparc/erc32 simulator.
Before I officially submit a patch series for review, I want to clarify three architectural details to ensure I am following RTEMS standards:
1. Managing Memory-Constrained Targets (YAML): In spcan03.yml and spcan04.yml, I currently require RTEMS_POSIX_API and manually excluded memory-constrained targets (e.g., not: or: [arch/avr, arch/v850]) since spawning multiple threads exhausts their memory. Is manually listing the boards the preferred way to skip these tests on small QEMU targets, or should I be using a min_memory requirement or standard .tcfg exclusions?
2. Standardizing Simulated Hardware Aborts: To validate error handling, I added a custom IOCTL using standard POSIX macros (RTEMS_CAN_IOC_VIRT_ABORT _IO('v', 1)) to can-virtual.c. This forces the virtual chip to drop the next frame and increment its simulated error registers. Is utilizing a custom IOCTL the acceptable approach for fault injection? If so, where is the most appropriate header to define this test macro so I do not pollute the public API?
3. Configuring RX Filters for can_2w (spcan04): I noted that opening a CAN edge initializes a default-deny filter. To fully port the two-way nature of can_2w, spcan04 needs to validate concurrent reads alongside the writes. What is the correct API call to explicitly open the RX filters during the test’s Init() phase so the receiver threads can properly capture the looped-back frames?
As for POSIX, it should be easy to start tester tasks as RTEMS only ones and for tests and memory constrained targets it can be useful.
The
RTEMS_CAN_FIFO_SIZE = 64
should be defined in some (ideally global) minimal targets override. It can be for example only 4
RTEMS_CAN_FIFO_SIZE = 4
Ad 2) seems reasonable or may be some IOCTL dedicated for debugging which would have this option as one of subcommands…
Ad 3) I hope that there should not be problem. Only deny is local delivery of the message to the sending filedescriptor. Other "open"s even of the single virtual /dev/can0 should see all send messages same as if they are connected trhough real bus on and open same controller or other ontroller on the other node. There is option how to suppress frames send by other applications through same controller but that filter bit should not be set in default Rx and Tx edges setup after open implicitly.
I am going to lunch with Michal exactly now so we will discuss that as well.
I am following up to see if there were any additional takeaways from your discussion last week.
Based on Pavel’s initial review, I am ready to finalize the code with the following adjustments:
Memory Footprint: Removing the YAML architecture exclusions and instead defining RTEMS_CAN_FIFO_SIZE = 4 for minimal targets.
Virtual IOCTL: Keeping the custom macro for now, unless you prefer I refactor it into a subcommand of a broader “Debug” IOCTL before submitting the Merge Request.
RX Filters: Modifying spcan04.c to open separate file descriptors so the tasks can natively read the looped-back frames.
If there are no further suggestions, I will proceed with these updates and open the formal Merge Request for the April tasks.