Same issue for the changes in the MR and for the main branch both.
Qemu doesnt seem to execute tests properly and hangs on the terminal.
For checking whether qemu runs. The log file was created.
rv32imafdc runs on virt machine configuration.
no graphic is used to display output on terminal itself.
On running test in rtems-test, the test face a timeout issue.
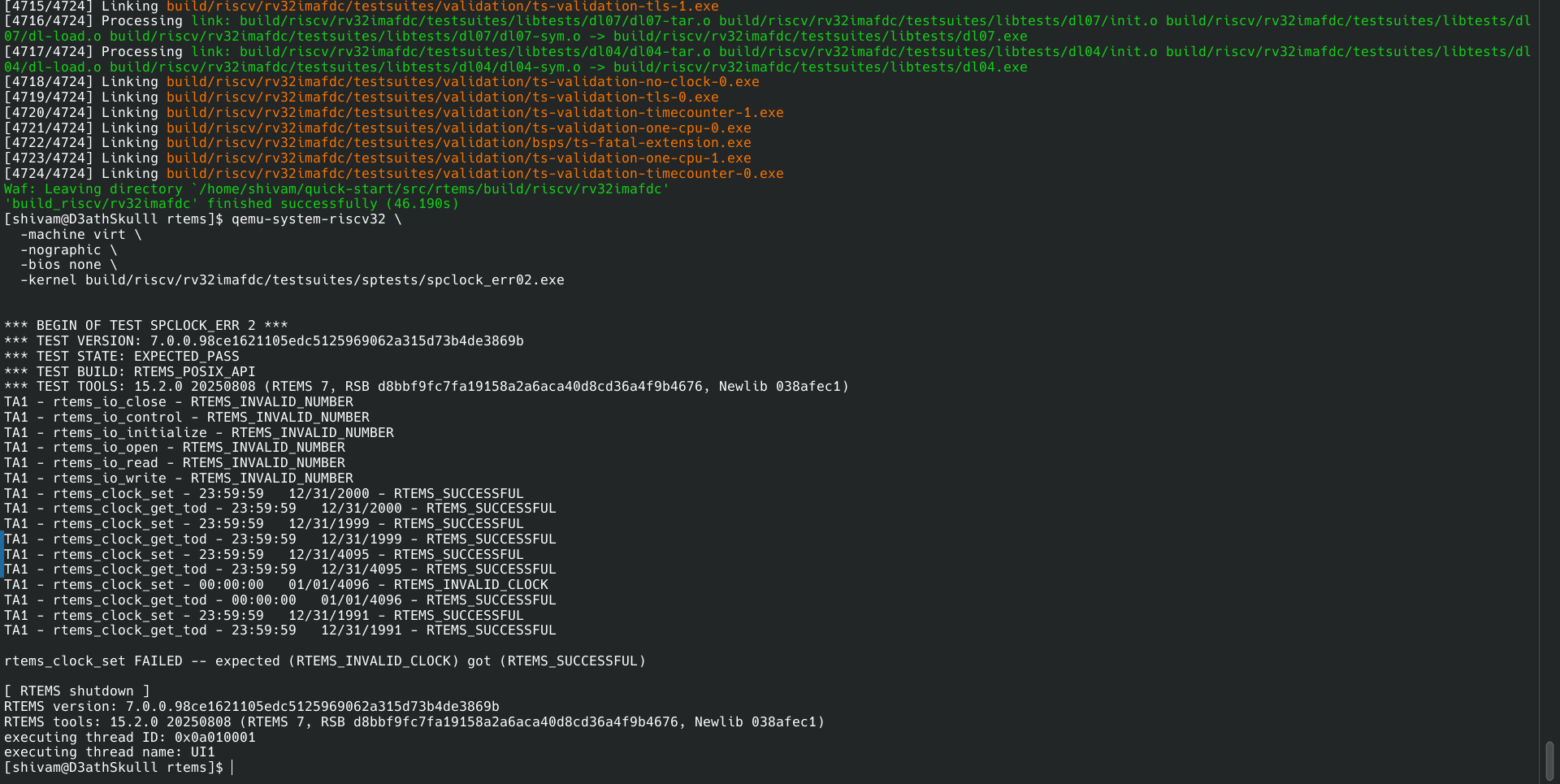
On inspecting the code in qemu.log while running with asm,cpu config.
There is this code which gets executed in an infinite loop.
This points out to a linker issue.
ok, The qemu command line to use is in our documentation, see
The one you used probably does not load the OpenSBI firmware, which may cause some issues. However, it should still work.
The next step would be to either use git-bisect to try to identify which commit the test stopped working on, or use gdb to find out where in the program it is hanging.
The register dump suggests this is inside the timer interrupt handler, since mcause = 7. You can use riscv-rtems7-objdump -d spclock_err02.exe > a.txt and inspect the PC and the MEPC addresses to see what is being executed. The fact that the PC and MEPC are nearly identical is suspicious. I would guess that there’s an interrupt happening while execution is handling the previous interrupt.
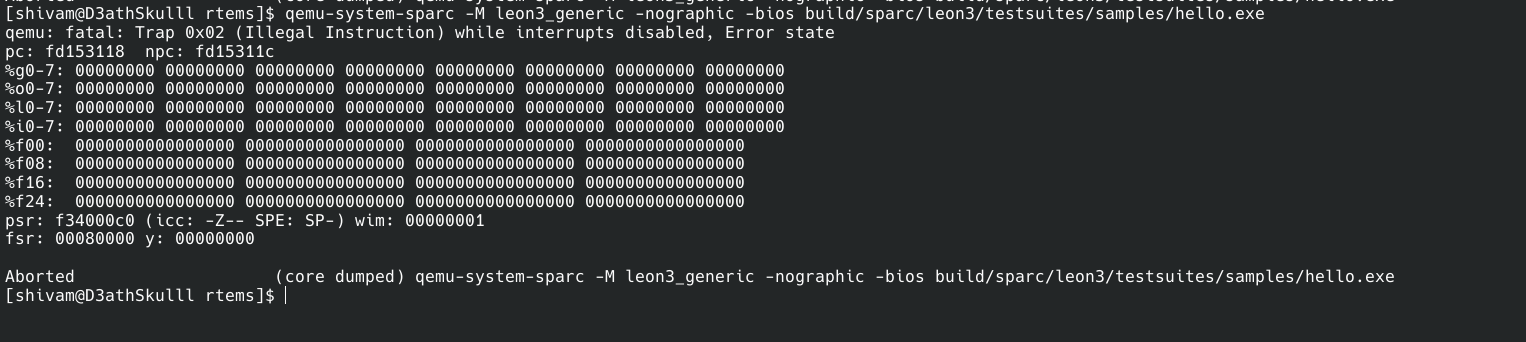
That’s curious, please double check. I don’t see this problem on rv64imafdc, and based on the bad commit, I would not expect any problems with sparc that is exactly this problem.
My bad, I have tested again on rv64imafdc I got proper output.
I have updated the spclock MR regarding the same.
I’ll create a new issue for this problem side by side
is this regarding leon3 listed as an issue on the gitlab?
Regarding the rv32 and the faulty commit.
I tried analysing and making some changes in start.S and bspsmp.c and clockdrv.c which were the files involved in this issue and here were my findings
Commented out early interrupt enabling in bspsmp.c to check if premature interrupts caused the issue. The hang persisted, ruling out simple interrupt timing as the root cause.
Reverted exception routing from direct handler to _RISCV_Vector_table. This ensured proper dispatching but did not resolve the looping issue.
Disabled timer interrupt initialization to test if a timer storm was causing repeated traps. The system still hung, proving the issue was not timer-related.
Adjusted stack pointer initialization from _begin to _end to avoid invalid memory access. No improvement was observed, ruling out basic stack misplacement.
Hypothesized that uninitialized memory could cause faults and tested reordering BSS clearing. The issue persisted, so memory initialization order was not the cause.
Can you suggest whats our best course of action here?
I narrowed down the problem by breaking at the first dispatch into _RISCV_Vector_table and backtraced to find there was a fatal error due to missing FDT, which pointed me to look at the bsp_fdt_copy and I found that execution was not reaching it during the boot process.